 Laboratoire ID-IMAG
Laboratoire ID-IMAG
(Montbonnot
Saint-Martin)
MENETRIEUX Marie-Laure
MARESCHAL Arnaud
Département RICM
Rapport de stage 2ème
année.
Magistère 2éme
année
Extension de
l'intergiciel
pour le calcul parallèle haute performance :
Inuktitut
Tome Principal
et
Annexes
Année
universitaire 2001-2002
Stage du
15/06/2002 au 15/09/2002
Introduction............................................................................................................................... 3
Objectifs du magistère............................................................................................................... 4
Plan du rapport.......................................................................................................................... 4
Etat de l’art................................................................................................................................ 5
1. Globus................................................................................................................................. 5
2. MPI (Message Passing Interface) :................................................................................. 11
environnement de programmation parallèle................................................................................................................ 11
3. PVM (Parallel
Virtual Machine)....................................................................................... 14
4. Harness............................................................................................................................. 15
5. PM2 (Parallel
Multithread Machine)............................................................................... 17
5.1 Madeleine................................................................................................................................................................... 18
6. PadicoTM.......................................................................................................................... 20
7. APACHE........................................................................................................................... 24
8. Synthèse............................................................................................................................ 24
Le projet APACHE : Athapascan et Inuktitut....................................................................... 25
1. Athapascan : une interface de programmation pour les
applications parallèles.............. 25
2. Inuktitut............................................................................................................................ 26
2.1 Présentation et Objectifs.......................................................................................................................................... 26
2.2 Fonctionnalité............................................................................................................................................................ 26
2.3 Fonctionnement des appels à distance ou message actif................................................................................... 27
2.4 Architecture d’Inuktitut........................................................................................................................................... 32
2.5 Exemple de programme Inuktitut :........................................................................................................................... 37
Passage à l’échelle et dynamicité........................................................................................... 40
1. Lancement......................................................................................................................... 40
2. Interconnexion.................................................................................................................. 43
Evaluation de performances................................................................................................... 46
1. Passage à l’échelle............................................................................................................ 46
2. Dynamicité......................................................................................................................... 46
2.1. Evaluation du coût en fonction du nombre de liaisons utilisées...................................................................... 46
2.2. Multidiffusion sur les différents réseaux.............................................................................................................. 47
2.3. Améliorations et perspectives............................................................................................................................... 50
Conclusions et perspectives..................................................................................................... 52
Annexes :.................................................................................................................................. 53
Annexe I : Interface du réseau TCP_net (Inuktitut) :......................................................... 53
Annexe II : La grappe du laboratoire ID-IMAG................................................................. 55
Glossaire :................................................................................................................................ 56
Bibliographie :......................................................................................................................... 58
Introduction
Depuis quelques années, l’augmentation de la complexité des applications informatiques dans les différents domaines de recherche scientifique et technique se traduit par un besoin croissant de puissance de calcul. La puissance des grosses structures de calcul, tels les supers-calculateurs, n'est plus suffisante pour couvrir ces besoins. De plus leur coût en fait des ressources peu accessibles.
C’est pourquoi certains logiciels ont déjà trouvé d’autres solutions pour obtenir les mêmes puissances, a un coût moindre. C’est notamment le cas d’un projet scientifique en radioastronomie appelé seti@home. Cette expérience exploite la puissance inutilisée de plusieurs millions d’ordinateurs connectés via Internet afin de procéder à l’analyse du rayonnement stellaire à la recherche d'émissions artificielles. Dans le cadre de la recherche génétique, un projet nommé décrypthon utilise également la puissance des ordinateurs connectés à Internet. Cette expérience effectue la comparaison des séquences de deux ensembles de protéines. Chaque protéine d’un ensemble est comparée avec chaque protéine de l’autre ensemble. Ainsi si les ensembles contiennent respectivement 10 et 20 protéines, alors 10*20=200 comparaisons de séquences seront effectuées.
L'assemblage de multiprocesseurs à l'aide de réseaux haut débit, appelé aussi grille de grappes, est à même de fournir la puissance nécessaire aux plus grosses applications. Une grappe (cf Annexe II), appelée aussi cluster, est formée par l’interconnexion de plusieurs PCs entre eux. La grappe est une structure homogène, c’est-à-dire que tous les PCs sont connectés sur un même réseau et qu’ils utilisent le même système d’exploitation. Le concept de grille peut être comparé aux infrastructures de distribution de l’énergie électrique. Les différents systèmes de production de l’énergie (centrales nucléaires, barrages hydrauliques, éoliennes...) sont reliés sur un même réseau puis utilisés indifféremment. Le consommateur ignore totalement l’origine géographique de la puissance. De même une grille informatique relie plusieurs systèmes de calcul (grappes, supercalculateurs,…) par des réseaux hétérogènes. Contrairement aux grappes, on peut observer, sur une même grille, des politiques de gestion différentes, ainsi que l’utilisation de plusieurs systèmes d’exploitation. On parlera principalement de grilles de grappes.
Afin d'utiliser au mieux de telles architectures, il est nécessaire de concevoir des intergiciels performants permettant une programmation de haut niveau au dessus de grappes ou grilles de grappes. Pour cela, l’intergiciel fournit une machine virtuelle. Son but est de simuler une machine parallèle de manière à ce que l’utilisateur ait l’impression de travailler sur une machine gérée par un seul système d’exploitation (celui de la machine virtuelle). Du point de vue de l’utilisateur, la machine virtuelle est formée d’un ensemble de nœuds pouvant communiquer par échange de messages. Un nœud équivaut à un processus exécutant une partie du code réalisant le calcul.
Objectifs du magistère
Au cours de notre stage nous avons été amenés à créer plusieurs modules d’un projet d’exploitation de grappes et de grilles, qui s’intitule Inuktitut. Inuktitut est un intergiciel qui va permettre de lancer des applications parallèles sur des grilles de grappes. Pour des raisons de portablilité et d’extensibilité, Inuktitut est construit sous la forme de différents modules. Le premier module créé constitue une couche de communication bas niveau. Il fournit une couche de portabilité pour les sockets Posix. Le second procure une couche de communication de haut niveau. Elle offre à l’utilisateur un réseau virtuel complètement maillé. Ce réseau virtuel a été implanté au-dessus de la couche TCP/IP.
Enfin nous avons réalisé des tests sur différents réseaux qui sont présentés à la fin du dossier. Le contenu des différents modules cités ci-dessus est détaillé dans le chapitre de présentation d’Inuktitut. Notre travail s’est orienté autour de deux thèmes : l’extensibilité des réseaux (passage à l’échelle) et la dynamicité de l’établissement des connexions.
Plan du rapport
Dans un premier chapitre, nous présentons les différents projets en cours qui traitent d’un sujet s’approchant de celui d’Inuktitut. Nous donnons les spécificités de chacun de ces projets ainsi que les avantages et inconvénients de chacun. Dans le chapitre suivant, nous décrivons le projet sur lequel nous avons travaillé. Ensuite, nous traitons de deux sujets concernant notre travail : le passage à l’échelle et la dynamicité. Nous donnons les différentes solutions possibles aux différents problèmes ainsi que les choix que nous avons adoptés, puis nous présentons les résultats des expériences d’évaluation de performance que nous avons réalisées. La définition de certains mots techniques se trouve dans le glossaire situé à la fin du rapport.
Etat de l’art
Nous allons maintenant présenter
les différents projets en cours permettant l’exploitation de grappes et de
grilles de grappes. Nous terminerons ces présentations par la description du
projet sur lequel nous avons travaillé dans le cadre du magistère : le
projet Inuktitut.
1. Globus
Le projet Globus travaille sur le concept de grille. Une grille est un ensemble hétérogène de ressources qui nécessite des outils de communication spécifiques. Nous allons donc d’abord aborder ce concept de grille plus en détail avant de décrire le projet Globus.
Il existe plusieurs sorte de grilles :
Les grilles d'informations qui permettent de partager les connaissances, comme Internet.
Les grilles de données pour
le stockage distribué à grande échelle, qui
sont utilisées par exemple par les fournisseurs de services de stockage
(Storage Service Provider).
Les grilles de calcul qui permettent d’agréger la puissance de calcul. Elles peuvent être composées de supercalculateurs associés à des grappes de PCs.
Les applications pour les grilles sont très nombreuses dans le domaine industriel comme dans le domaine scientifique. Elles permettent l’analyse de grands volumes de données, la conception collaborative de produits, l’intégration en temps réel de chaînes de production et d'approvisionnement. De même un utilisateur pourra se servir de façon transparente de machines réparties sur différents continents. Dans ce rapport nous nous intéressons plus particulièrement aux grilles de calcul pour le calcul parallèle.
Architecture d’une grille
Plusieurs particularités
architecturales posent des problèmes de gestion à qui veut gérer une grille.
Tout d’abord une grille est formée de ressources hétérogènes. Ceci pose le
problème de communications entre ces différentes ressources. Par exemple si la
grille est formée de deux grappes de PCs, dont chacune fonctionne sous un
réseau différent (SCI, Myrinet), et d’un supercalculateur, un protocole de
communication devra être établi entre ces différentes ressources. De plus les
réseaux reliant ces grappes ne sont pas forcément homogènes au niveau de la
capacité de débit, donc il faudra répartir la charge sur ces liens. Ensuite, la
taille d’une grille est en général à l’échelle d’un pays. Cette taille amplifie
le problème de partage des ressources. Ces ressources pouvant être des
processeurs, des fichiers. En effet, lorsque les utilisateurs demandent
l’attribution de ressources de calcul, la coordination du partage des
ressources est importante pour que ces ressources soient bien réparties aux
différents utilisateurs. Il faut également veiller à ce que la charge soit bien
répartie sur la grille. Un autre problème des grilles est que les propriétaires
de ressources peuvent s’ajouter ou se retirer à leur gré de la grille. De plus,
le grand nombre de ressources disponibles implique qu’il y aura régulièrement
des ressources indisponibles (pour cause de panne), ou des ressources venant
s’ajouter. Il faut donc un gestionnaire de la dynamicité de ces ressources.
Pour désigner un groupe
d’individus ou d’institutions qui partagent les mêmes ressources on parlera
d’organisation virtuelle (OV). Une organisation virtuelle peut être un fournisseur
de service de stockage (SSP), les membres d’un consortium d’entreprises
travaillant sur le même projet, les
membres d’une entreprise internationale, ou les membres d’un centre de
recherche.
Les OV varient donc dans leur but, taille, structure, durée.
Mais elles ont toutes besoin d’un grand contrôle sur le partage des ressources,
la sécurité.

Figure 1 : Exemple
d’organisations virtuelles utilisant les ressources d’une grille composée de 2
grappes de PC et de ressources de données.
Un organisation physique peut faire parti de plusieurs organisations virtuelles en partageant ses ressources. Sur la figure 1 nous voyons 2 organisations physiques (les ovales), et 2 organisations virtuelles ( P et Q). P qui relie les participants d’un laboratoire de recherche météorologique et Q, qui relie un centre de prévisions météorologiques. L’organisation physique de gauche participe dans P, celle de droite dans Q. Le laboratoire a décidé de partager sa puissance de calcul inutilisée avec le centre de prévisions, et ce dernier a accepter de laisser l’accès à ses données au laboratoire.
Le partage de ressource
dépend du propriétaire. En effet, pour des raisons commerciales ou de
confidentialité, le propriétaire doit pouvoir gérer explicitement l’accès des
ressources qu’il fournies. Chaque propriétaire défini donc des contraintes sur
ses ressources, sur ce qui peut être fait, quand, par qui. Par exemple, un
participant de l’OV P peut permettre a
ses partenaires d’ OV d’utiliser son service de simulation seulement pour
résoudre des problèmes simples.
Toutes ces contraintes
peuvent varier au cours du temps, tout comme le nombre de personnes autorisées
ou le nombre de ressources.
L’interopérabilité est un des soucis principal de l’architecture des
grilles. En effet dans les grilles, les participants peuvent se rajouter
dynamiquement à partir de différentes plates-formes, langages et environnements
de programmation. L’interopérabilité nécessite donc des protocoles communs.
C’est pourquoi l’architecture de la
grille est avant tout basée sur des protocoles définissant les mécanismes par
lesquels les utilisateurs de la grille et les ressources disponibles
communiquent.
La figure 2 décrit
l’architecture d’une grille en donnant pour chaque couche des exemples de
services qui peuvent être utilisés dans ces différentes couches. Cette
architecture est faite de telle sorte que le plus possible d’applications
puissent l’utiliser, et de même, qu’elle puisse s’implanter facilement sur un
large éventail de ressources.

Figure 2 : Description de l’architecture en
couche d’une grille
Globus
Le projet Globus est un projet de recherche et
développement qui a pour objet de créer des services pour l’utilisation des
grilles pour le calcul numérique à hautes performances et à grande échelle.
La suite logicielle
développée se nomme Globus Toolkit qui
correspond à un outil pour utiliser
des grilles informatiques. Globus fournit des logiciels pour l'infrastructure
des informations, la gestion des ressources, la communication, la détection des
fautes, la sécurité, et la portabilité.
Les principaux services
proposés par Globus Toolkit sont les suivants:
Module de gestion des ressources :
Pour gérer la demande de
ressources de calcul (de processeur ) par les utilisateurs, Globus fournit des
services d'allocation de ressources, de création de processus, de monitoring,
et de gestion. Ce module est le module GRAM (Globus Ressource Allocation
Manager).
Module de sécurité :
L’authentification pour
accéder aux ressources est un processus assez coûteux. Ce module fournit un
système d'authentification dit "single sign on", c'est-à-dire que
l'utilisateur a besoin d’une seule connexion pour accéder à toutes les
ressources de la grille. Ce module s’appelle GSI (Globus Security Interface).
Module de recherche et de monitoring :
La grille étant dynamique, il y a besoin de savoir quelles ressources sont disponibles et quel est leur état. C’est pourquoi Globus fournit un mécanisme de recherche de données ainsi que d'informations sur l'état de la grille, du réseau, de la location des ressources, c’est le module MDS (Monitoring & Discovery Service).
Module de gestion de fichiers de données :
Pour simplifier l’exécution d’applications à distance le module GASS (Global Access to Secondary Storage ) permet aux programmes d'écrire et de lire à distance sans avoir à se connecter manuellement ou avoir à installer un système de fichiers distribués.
Nexus :
Nexus est le noyau de
communication et d’exécution de la machine virtuelle fournit par
l'environnement Globus. La machine virtuelle sur laquelle Nexus va s’exécuter
pourra être soit une grappe, soit une grille de calcul, contrairement à la
plupart des bibliothèques existantes qui fonctionnent seulement sur des
grappes.
Au lancement de
l’application, un certains nombre de nœuds composent la machine virtuelle. Cet
ensemble peut évoluer dynamiquement soit par ajout, soit par suppression de
noeud.
A l'intérieur de chaque
noeud des espaces d'adressages sont créés. Pour des raisons de sécurité le code
à exécuter sur chaque nœud est confiné dans ces espaces d’adressage similaires
à ceux d'un processus UNIX Ces espaces d’adressages sont appelés contextes. Les
threads sont créés et exécutés à l’intérieur de ces contextes. Plusieurs contextes peuvent
être créés sur un même noeud, et chaque contexte peut avoir plusieurs threads
en son sein.
Globus fournit une
bibliothèque de thread à partir des threads POSIX, avec les opérations basiques
sur les threads comme la création, la destruction, l’exclusion mutuelle et la
synchronisation.
A l'intérieur d'un même
contexte la communication est faite par mémoire partagée. Nexus offre une
primitive de communication à distance qui est la demande de services distants .
C’est une primitive de communication asynchrone. Le destinataire n’est pas
bloqué en attente d’un message de l’émetteur, mais lors de l’arrivée d’un
message cela déclenche immédiatement l’exécution d’un service. Si Nexus est
utilisé sans thread, le fonctionnement est celui des messages actifs. Sinon un
démon, qui est à l’écoute de l’arrivée de messages, créé un thread dédié à
l’exécution de la requête, ou exécute lui-même cette requête.
Module de détection de pannes :
Globus fournit un système de détection de pannes, le HBM (HeartBeat Monitor), qui détecte et rapporte les pannes qui lui sont signalées par les processus. Il permet aussi de détecter l’arrivée d’exceptions. Le système « HeartBeat » fonctionne suivant le principe suivant : les processus en cours doivent envoyer régulièrement des signaux au système de détection pour signaler leur état. Ainsi les pannes sont facilement repérées soit par un signal de panne, soit par l’absence de message.

Figure 3 :
Structure générale de Globus
La figure 3 reprend les
différents services de Globus, et présente sa structure. Le standard de
programmation parallèle MPI-1.1 a été implanté dans une version spécifique à
Globus : MPICH-G2. Globus peut être implanté sur plusieurs types de
réseaux. Ce qui permet aux grappes composant des grilles d’être de types de
réseaux différents. Globus a été validé sur de telles architectures de grilles
composées de milliers de nœuds. Mais, une contrainte de Globus est qu’il
utilise un protocole d’exécution distante dédié. Ceci oblige ces grappes voulant
participer à la grille à modifier leur configuration. Malgré cela, Globus est
aujourd'hui l’un des projet les plus complet qui existent pour travailler sur
les grilles.
2. MPI (Message Passing Interface) :
environnement de programmation parallèle
MPI (Interface de passage de message) est un standard de communication de haut niveau permettant de développer des applications parallèles distribuées. MPI fournit une interface qui permet aux processus d’un programme parallèle de communiquer entre eux. Ce standard a été défini pour améliorer PVM, et former un consensus autour d’un standard.
La communication dans MPI :
Les primitives de
communication de MPI sont de type send()/recv(). Elles permettent à une paire
de processus – l’émetteur et le destinataire - d’échanger des messages entre
eux. Ces primitives de communication sont bloquantes (synchrones) ou non
bloquantes (asynchrones). La primitive asynchrone possède un paramètre requête
qui permet de vérifier ultérieurement la terminaison de l'opération.
Le destinataire des
communications appartient à un plan de communication désigné par une
abstraction de haut niveau appelée « communicateur » . Le
communicateur est un paramètre obligatoire pour toutes les primitives de
communication. Le communicateur pourra désigner aussi bien une machine qu’un
processus.
Le standard MPI-1 définit
les types élémentaires de données communicantes (vecteurs d'entiers, flottants,
etc ) et des constructeurs de type permettant de décrire l'implantation en
mémoire de données non contiguës. Il dispose aussi d'opérateurs spécifiques
d'emballage/déballage dans le cadre d’application distribuée sur un
environnement hétérogène.
Topologie virtuelle :
La topologie est un attribut
optionnel aux communicateurs utilisée pour fournir un mécanisme de désignation
des processus appartenant à un même ensemble de destinataire. MPI définit des
fonctions pour assurer les mouvement efficaces de données prenant en compte une
organisation spatiale des processus en forme de grille (cartésien) et graphe.
Ce mécanisme de désignation peut encore, pour une implantation particulière de
MPI, aider au placement efficace de processus en respectant la géométrie
physique du matériel.
Primitives de communication collectives :
MPI permet de réaliser des
opérations de diffusion, regroupement, distribution et réduction sur des ensembles de processus. Ces primitives
doivent être réalisées par tous les processus de l’ensemble de processus
affecté. Pour parler de ces ensembles de processus on va parler de groupe.
Processus/Groupe :
Une application MPI est un
ensemble de processus appartenant au groupe « world ». Ce groupe
initial peut être subdivisé en plusieurs sous-groupes. Par là, un processus
peut appartenir simultanément à plusieurs
sous-groupes. Un groupe représente un plan de communication distinct d'un autre
groupe même si les interlocuteurs sont les mêmes. Un groupe est représenté par
un communicateur.
Les
extensions MPI-2
Le standard MPI-1 a été très
largement utilisé. Pourtant certains point importants manquaient comme les
opérations d’accès à une mémoire distante,
la gestion des machines et des tâches, les opérations d’entrées/sorties
sur fichier, et le support explicite de la multiprogrammation légère. C’est pourquoi
le standard MPI-2 a été défini. Il possède les extensions suivantes :
·
Gestion
dynamique de processus :une gestion dynamique des processus a été intégrée dans
le standard MPI-2.
·
Entrées
et sorties parallèles : MPI-2 définit une interface qui donne à l’utilisateur
un accès transparent aux ressources disques et fichiers réparties sur les
différents nœuds.
·
Accès
à la mémoire à distance : les écritures et lectures à distance peuvent,
dans ce nouveau standard, se faire de manière asynchrone. Le protocole de type
send()/recv() est remplacé par des messages actifs.
·
Aide
à la programmation et au débogage : une série de conventions ont été établies pour permettre l’utilisation de
bibliothèques, ou un ensemble de fonctions écrites dans un autre langage.
·
Extensions
des opérations collectives : MPI-2.0 lève la restriction que seuls les
processus appartenant à un même groupe peuvent utiliser les primitives de
communications collectives. L’autre extension est l’apparition de versions non
bloquantes pour ces opérations.
·
Multiprogrammation
légère : En calcul parallèle, quand on dispose de multiprocesseurs il est intéressant de pouvoir communiquer par
passage de message bien sûr mais aussi
par threads à l’intérieur du multiprocesseur. Le standard MPI-2 établit donc
les conditions pour qu'une implantation de MPI soit conforme à l'utilisation de
threads, et définit le comportement des threads par rapports aux appels MPI.
Conclusion
Dans cette version de MPI
aucun protocole de routage n’est défini pour utiliser plusieurs réseaux
physiques. Cette fonction est laissée libre aux implantations. Par exemple la version MPICH-G2, la version de Globus,
l’implante. Mais il n’existe pas encore d’implantation libre complète de MPI-2.
3. PVM (Parallel Virtual Machine)
PVM [3] fournit un intergiciel
permettant d’exploiter plusieurs ressources de calcul (grappes de SMP). Il
permet à l’utilisateur de programmer au-dessus d’une grappe à l’aide d’un
ensemble de processus communiquant par messages.
Les trois principaux choix qui ont guidé la conception de PVM sont :
- Une interface simple permettant le passage de messages, le contrôle de la machine virtuelle, le contrôle des tâches.
- Une transparence qui permet de construire un programme fonctionnant sur différentes architectures, différents réseaux et différents systèmes d’exploitation.
- Un dynamisme permettant de changer la configuration de la machine virtuelle et de modifier le nombre des tâches en cours d’exécution.
Dans PVM, le processus initial créé lance un démon maître. Tous les autres démons seront démarrés par le démon maître en utilisant le protocole rsh (remote shell). Lors de l’expansion de la machine virtuelle, un nouveau démon sera démarré sur chaque nouvelle machine. Celui-ci se connectera au démon maître auquel il donnera sa configuration. En effet, toutes les tables de configuration des systèmes sont mémorisées par le maître et celui-ci doit donc continuer à tourner tant que la machine virtuelle fonctionne. Si le démon maître disparaît, tous les démons non maîtres vont s’interrompre et la machine virtuelle terminera. Pour la stabilité du démon maître, quelques situations de concurrence ont été éliminées lors des choix de l’implantation : ainsi, deux machines virtuelles démarrées séparément ne peuvent pas être jointes en une seule machine virtuelle. De même une machine virtuelle ne peut pas être divisée en plusieurs machines distinctes. Les machines virtuelles ne peuvent que croître et décroître.
L’espace de communication est restreint à la machine virtuelle. Aucun message PVM ne peut sortir de cette machine virtuelle, pour aller, par exemple, à destination d’une autre machine virtuelle ou en direction d’un processus extérieur.
PVM est basé sur une notion de tâche. Chaque nœud de la machine virtuelle exécute plusieurs tâches simultanément. Ces tâches peuvent communiquer entre elles par l’envoi de messages. Afin de réaliser le routage des messages, il est nécessaire de numéroter les tâches. Ainsi chaque tâche possède un identifiant donné par la machine hôte.
PVM possède une notion de dynamisme. En effet, PVM permet au programme d’ajouter et de retirer dynamiquement des ressources. Cependant un surcoût de performance est souvent dû à cette flexibilité.
Certaines applications nécessitent l’utilisation d’un nombre dynamique de nœuds. Toutefois cette dynamicité pose plusieurs problèmes. Le premier consiste à trouver ou créer le nouveau nœud. Ceci est indiqué par l’utilisateur de la machine virtuelle. Le second problème est de répartir équitablement les charges de calcul entre les différents nœuds. Au cours de l’évolution de l’exécution du programme, certains nœuds peuvent être sollicités plus que d’autres. C’est pourquoi les concepteurs prévoient d’ajouter à PVM un système de répartition de charge. Pour cela, il faut avoir la possibilité de faire migrer une partie des tâches présentes sur la machine surchargée. Comme les tâches sont numérotées par la machine qui les héberges, celles qui migrent doivent changer d’identifiant. Ceci pose des problèmes dans la numérotation des tâches ainsi que dans le routage des messages. De plus un autre problème se pose lorsque l’on veut faire migrer une tâche ayant ouvert un fichier. Ce fichier sera invalide sur le nouveau système. Ce sont ces nombreux problèmes que PVM souhaite maintenant résoudre.
4. Harness
Harness [4] est un intergiciel actuellement développé dans les laboratoires de sciences informatiques de l’université du Tenessee. L’objectif de ce projet est de compléter les manques observés dans PVM. Ainsi, Harness permet la fusion de deux machines virtuelles. L’intergiciel est basé sur la programmation par composants[?].
Harness [2] a pour but une gestion flexible de ressources distribuées utilisées pour le calcul haute performance. Voici ses principaux critères de conception :
- Gestion flexible des composants qui composent une ou plusieurs machines virtuelles.
- Capacité de modifier ou d’ajouter dynamiquement des services à la machine virtuelle.
- Possibilité d’interaction entre plusieurs machines virtuelles.
L’architecture de HARNESS se présente sous cette forme :

Le noyau permet de charger et de lancer des composants aussi bien localement
qu’à distance. Il est conçu pour être modulaire et extensible. Son interface
est minimale : elle permet de charger/décharger et de lancer/arrêter des
composants. Elle permet également de consulter le contenu de l’annuaire.
Le démon est composé d’un noyau et d’un ensemble de composants. Il répond aux requêtes provenant de l’application locale ou d’un démon distant.
La machine virtuelle est composée d’un ensemble de démons qui interagissent et fournissent les services de communication, le contrôle du processus, la gestion des ressources, et la détection des fautes.
Un service d’annuaire distribué mémorise les données de façon à ce qu’elles soient accessibles à partir de n’importe quel composant ou application de la machine virtuelle. Il contient la liste des machines présentes dans la machine virtuelle, les composants présents, les bibliothèques que les applications doivent charger pour participer, ainsi que la liste des groupes dynamiques de tâches constituant l’application parallèle. Son interface permet d’insérer une donnée, de retirer une donnée, de détruire une donnée et de récupérer la liste de toutes les données. L’annuaire fait office d’espace mémoire distribué.
Un mécanisme gère le dynamisme du système à travers les opérations sur le service d’annuaire.
Contrairement à PVM, les composants ne se connectent pas grâce à un processus maître partagé mais par l’utilisation d’un annuaire partagé qui peut être implanté de manière distribuée et tolérante aux fautes. Tous les composants obtiennent leur identité grâce à ce robuste annuaire distribué. L’intérêt d’utiliser un annuaire vient de la possibilité de fusionner deux machines virtuelles en une seule en fusionnant simplement leur annuaires respectifs. De même certains composants peuvent former une nouvelle machine virtuelle en créant un nouvel annuaire et en retirant leurs entrées de l’ancien annuaire. Ainsi on obtient deux machines virtuelles distinctes.
De plus, Harness autorise l’accès à des ressources extérieures à la machine virtuelle. Par exemple, Harness permet de communiquer avec des nœuds appartenant à une autre machine virtuelle. Ce type d’accès était impossible dans PVM.
L’objectif de HARNESS est de fournir un robuste service de résolution de nom, efficace, tolérant aux fautes et qui passe à l’échelle. Sa conception par composant permet à cet intergiciel d’être facilement extensible.
5. PM2 (Parallel Multithread Machine)
Le noyau exécutif PM2 est un environnement de programmation parallèle portable conçu pour être le noyau commun aux différentes couches logicielles du projet ESPACE (Execution Support for Parallel Applications in high performance Computing Environments). Ce projet propose un modèle de programmation et d’exécution pour la réalisation d’applications parallèles irrégulières sur des machines distribuées. L’idée de base de ce projet est d’atteindre une « virtualisation globale » des architectures sous-jacentes pour supporter de façon efficace et transparente l’exécution d’une application sur un système distribué quelconque. PM2 fournit un environnement multithreadé distribué qui est conçu pour faire fonctionner efficacement des applications parallèles sur des architectures distribuées. Son objectif est d’améliorer les performances sur des architectures de type grappes de nœuds multiprocesseurs (SMP) en évitant d’avoir à faire le compromis entre efficacité et portabilité. PM2 est hautement portable et fournit un environnement efficace. Il inclut sa propre politique d’ordonnancement, supporte la migration des processus et fournit un mécanisme de répartition dynamique de charge.
PM2 possède deux composantes logicielles. La première s’appelle Marcel [?]. Elle fournit une gestion performante des threads. Cette composante ne sera pas détaillée dans ce rapport. La seconde composante est intitulée Madeleine. Dans la partie suivante, nous allons nous intéresser à cette composante qui est le noyau de communication de PM2.
Voici la structure générale de PM2 :

5.1 Madeleine
Madeleine [5] est une interface générique de communication pour applications multithreadées hautes performances. Elle permet de manipuler dans une même application plusieurs protocoles réseaux sur différents réseaux physiques. Madeleine choisit le protocole réseau convenant le mieux aux besoins de communication de l’application. Elle est capable d’exploiter pleinement les faibles latences et les larges bandes passantes que procurent des réseaux haut débit tels que Myrinet, FDDI ou SCI. L'originalité de Madeleine est de permettre une sélection dynamique et autonome d'optimisations de transmission des données en fonction des contraintes exprimées par l'application. Pour cela, elle développe un mécanisme qui sélectionne dynamiquement la méthode de transfert la plus appropriée pour un protocole de réseau donné en tenant compte de la taille des données et du rapport latence/débit. Une des principales optimisations consiste à utiliser des protocoles de type « zéro copie » (cf. chapitre Fonctionnement des appels à distance ou message actif). Chaque copie générant un surcoût important, ces types de protocole limitent le nombre de recopies des données entre les différentes couches réseaux.
Pour la communication entre les nœuds, deux objets sont utilisés : les canaux (channels) et les connexions. Une connexion correspond à une liaison point-à-point entre deux nœuds, entre deux processus appartenant à la même session. Un canal est une liste de connexions. Toutes les connexions d’un canal utilisent une même interface réseau ainsi que le même protocole réseau. Un canal n’interfère pas avec un autre.
Les différents nœuds communiquent par envoi de messages, en utilisant des messages actifs. Deux types de données peuvent être insérés dans ces messages : les données immédiates et les données différées. Les données immédiates sont accessibles dès réception du message, avant même que celui-ci ne soit entièrement reçu. Au contraire, il faut attendre la réception complète du message avant de pouvoir accéder aux données différées. L’utilisation de données immédiates est pénalisante en latence et en bande passante (cf. chapitre fonctionnement des appels à distance ou message actif), c’est pourquoi il est préférable dans la mesure du possible d’utiliser des données différées qui évitent des copies de données. Ces deux types de données sont différenciés par leur méthode d’envoi et de réception. Lors de l’insertion d’une donnée dans un message, les méthodes d’émission et de réception choisies sont indiquées par l’utilisateur au moment de l’envoi du message.
Nous allons maintenant détailler la construction d’un message que l’on pourra plus tard comparer avec la construction d’un message Inuktitut.
Voici l’interface fournie par Madeleine II :
mad_begin_packing initialise un nouveau message
mad_begin_unpacking initialise une réception de message
mad_end_packing termine une émission
mad_end_unpacking termine une réception
mad_pack emballe un bloc de données
mad_unpack déballe un bloc de données
Pour envoyer un message, il faut appeler la fonction mad_begin_packing en donnant en paramètre le canal sur lequel on veut écrire et le numéro du nœud distant à qui l’on veut envoyer le message. L’appel à cette fonction va nous fournir une connexion avec le nœud distant. C’est sur cette connexion que les données seront envoyées. Ensuite les blocs de données sont inclus dans le message grâce à la fonction mad_pack qui prend en paramètres un pointeur sur les données, la taille des données ainsi que les protocoles d’émission et de réception. Il existe trois protocoles d’émission. Le premier indique que la donnée doit immédiatement être mise dans le message afin que l’espace mémoire puisse être réutilisé ; le deuxième interdit à Madeleine d’accéder à la donnée avant l’appel de la fonction mad_end_packing ; et le troisième protocole qui est celui par défaut signifie que la donnée sera insérée le plus efficacement possible au plus tard lors de l’appel de mad_end_packing. L’appel à la fonction mad_end_packing indique la fin de la construction du message.
Du côté de la réception, la fonction mad_begin_unpacking initialise la réception, ensuite les données sont récupérées par l’appel à mad_unpack. L’arrivée des données se fait dans l’ordre dans lequel elles ont été insérées dans le message. Les protocoles d’émission et de réception de la fonction mad_unpack doivent être les mêmes que ceux fournis à la fonction mad_pack lors de l’envoi. Il existe deux protocoles de réception. Le premier protocole indique l’utilisation de données immédiates et le second celle de données différées. Les données différées ne seront accessibles que lorsque la fonction mad_end_unpacking aura été appelée. L’appel à mad_unpack achève la réception et permet de vérifier que tout le message a été reçu.
La conception de Madeleine a été réalisée en deux couches : l’une permet la portabilité de l’application et l’autre assure la gestion des tampons.
La couche Buffer Management Modules (BMM) implante différentes politiques de gestion des tampons. L’allocation et la désallocation des tampons dépend du réseau physique et du protocole de communication utilisé. Certains protocoles permettent, par exemple, l’utilisation d’un mode «Direct Memory Acces» ce qui améliore les performances en écrivant les informations reçues directement en mémoire. Il est donc nécessaire d’adapter l’allocation des tampons en fonction des capacités du protocole utilisé.
La couche Transmission Module (TM) permet la portabilité de l’application. Un BMM est choisi en fonction du protocole de communication utilisé. A chaque extrémité du canal, les mêmes protocoles doivent être utilisés.
Madeleine fonctionne actuellement au dessus de nombreux protocoles de communication tels que VIA[6], SCI[7], MPI, PVM and TCP.
Madeleine II a également été intégré dans MPICH, une implantation du protocole MPI. L’objectif étant de laisser MPICH/MadeleineII transparent par rapport au nombreux protocoles de communication de Madeleine II.
Le prochain objectif est de faire fonctionner Madeleine II sur des clusters connectés par des réseaux hétérogènes (grilles de grappes) en fournissant un routage efficace à travers les différents protocoles de communication haute performance.
6. PadicoTM
Padico est un intergiciel permettant la programmation sur des grappes et des grilles de grappes. Il est conçu pour le calcul parallèle haute performance et pour la programmation distribuée. C’est un environnement ouvert pour l’intégration de plusieurs exécutifs qui leur permet de partager efficacement les ressources réseau d’une grille.
Voici ses principaux objectifs :
- Le programmeur doit pouvoir
utiliser les méthodes les mieux adaptées à chaque exécutif. (en fonction des
différentes contraintes du réseau: mémoire partagée, passage de message,
…)
- Tous les exécutifs doivent bénéficier des meilleures performances possibles (processeur, réseau)
- Plusieurs exécutifs doivent pouvoir être utilisés en même temps (couplage de code) sans qu’il n’y ait concurrence.
Le logiciel Padico est principalement composé des deux entités suivantes : PadicoControl et PadicoTM :
Les applications sont chargées et déchargées dynamiquement sous forme de modules dans des processus déjà démarrés sur les nœuds de la grappe. Ces opérations distantes sont contrôlées par PadicoControl.
PadicoTM est l’environnement d’exécution de Padico. Il est composé d’un noyau qui fournit les communications réseau haute performance et le « multithreading ». Les performances des communications et des threads sont dues à l’utilisation de Madeleine et de Marcel fournis par PM2. Le noyau de PadicoTM (PadicoTM core) fait en sorte de pouvoir exécuter plusieurs applications simultanément dans un but de coopération plutôt que de compétition.
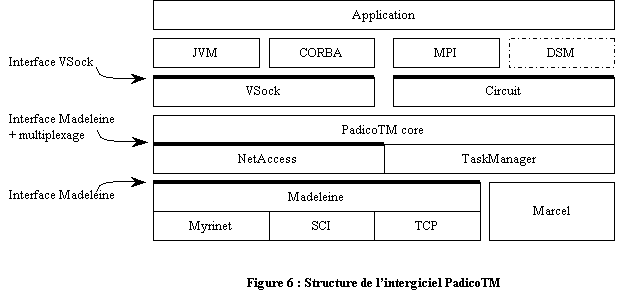
PadicoTm est très modulaire, en voici la structure générale :
Le module Madeleine est une bibliothèque de communication qui fournit une API uniforme pour des réseaux variés tels que Myrinet, SCI ou Ethernet. Elle permet une portabilité vis-à-vis du réseau tout en obtenant de bonnes performances notamment grâce aux méthodes sans copie de données en mémoire (cf. chapitre PM2).
De nombreux exécutifs ou applications utilisent le « multithreading ». Cependant il est probable que des applications différentes utilisent des politiques de « multitreading » incompatibles ou tout simplement des bibliothèques différentes. Ces aspects rendent périlleuse la cohabitation de plusieurs exécutifs multithreadés au sein d’un même processus. Au pire la cohabitation ne fonctionne pas, au mieux il y a simplement concurrence ce qui conduit à une sous-exploitation des ressources disponibles. Pour résoudre ces aspects, PadicoTM sert d’intermédiaire pour la gestion du « multithreading ». Ainsi tous les exécutifs utiliseront la même bibliothèque : celle fournie par PadicoTM. Une solution aurait été d’utiliser les threads Posix (pthread), cependant il est connu que les threads Posix et les communications réseaux ne cohabitent pas de manière optimale [1]. C’est pourquoi le choix s’est orienté vers l’utilisation de la bibliothèque de « multithreading » Marcel. La bibliothèque TaskManager fournit donc une interface proche de Posix (possibilité de callback afin d’éviter l’utilisation de boucles d’attentes coûteuses en performance) en utilisant la bibliothèque Marcel (cf. chapitre PM2).
NetAccess est le module de communication réseau de Padico. Il gère le multiplexage des threads pour permettre l’utilisation de Madeleine qui n’est pas multi-client. Ce module permet de décharger les exécutifs de la gestion des threads de communication. Le multiplexage n’ajoute pas de paquets supplémentaires sur le réseau car il est réalisé par concaténation d’une entête aux paquets existants. Ce module permet donc d’améliorer les performances en évitant la concurrence entre les exécutifs. De plus, le coût dû au multiplexage est négligeable et la latence logicielle est imperceptible.
Au dessus de NetAccess se trouve la couche Vsock. Elle gère plusieurs protocoles et utilise celui convenant le mieux au matériel disponible. Pour chaque lien (désigné par l’adresse IP et le numéro de port) Vsock détermine s’il peut utiliser Madeleine ou s’il doit se limiter au protocole standard TCP/IP. L’interopérabilité étant cruciale, les sockets ouvertes par Vsock doivent pouvoir être connectées de façon transparente à des sockets standard TCP/IP. A la différence de TCP/IP, Vsock ne supporte pas les flux continus cependant les services fournis devraient suffire pour atteindre les objectifs visés par Padico.
NetAccess fournit un réseau de communication virtuel qui s’étend sur tous les nœuds de la grappe où le code est déployé. Son interface permet l’accès aux canaux de communication. Un module intitulé Circuit permet l’ajout d’une notion de groupes. Ainsi un circuit est défini comme un lien de communication restreint à un groupe. Ce lien est défini au-dessus des canaux statiques implantés dans NetAccess.
Des expérimentations ont été réalisées sur des grappes de bi-Pentium équipés de réseaux Ethernet-100 et de Myrinet-2000. Le débit observé est excellent sur Myrinet, car il atteint 96% du débit atteignable avec Madeleine seul. Les latences observées sont les mêmes que celles observées avec MPICH/Madeleine.
PadicoTM est seulement dans sa phase initiale. Quelques améliorations concernant notamment la sécurité, le déploiement et la tolérance aux fautes sont en cours de réalisation.
7. APACHE
Le projet APACHE, acronyme de Algorithmique, Programmation Parallèle et Partage de Charge, est développé au sein du laboratoire Informatique et Distribution (ID) de l'Institut d'Informatique et de Mathématiques Appliquées de Grenoble (IMAG). APACHE est un projet de recherche sur le calcul parallèle. Il propose une approche de la programmation des machines parallèles pour le calcul haute performance qui permette d'atteindre un bon compromis performance-portabilité, indépendamment des particularités de chaque machine et de chaque application. Les applications visées par le projet APACHE se situent dans le domaine du calcul scientifique où les algorithmes présentent un caractère irrégulier (on n’a pas de connaissances préalables du comportement de l’application en termes de phases de calcul, de communication et de durée) et ont un besoin de haute performance. Ce projet est composé des deux entités suivantes : Inuktitut et Athapascan.
Inuktitut fournit un environnement d’exécution à base de processus légers communiquants. Athapascan constitue un environnement de programmation efficace et portable. Il permet notamment une répartition automatique de la charge de calcul. Ces deux entités seront détaillées dans le chapitre de présentation du projet APACHE.
8. Synthèse
Comme nous venons de voir, la plupart des projets d’implantation de machines virtuelles permettant l’exploitation de grilles de grappes, ont pour objectifs la portabilité, le passage à l’échelle et le « multithreading ».Ils utilisent tous des communications point-à-point. De même, beaucoup d’entre eux utilisent des protocoles de communication performant de type zéro-copie. Cependant, rares sont ceux ayant la possibilité de fusionner plusieurs machines virtuelles. Peu d’entre eux supportent le multi-réseau, indispensable pour l’exploitation de grilles de grappes hétérogènes. C’est notamment dans le but de combler ces manques que le projet Inuktitut est développé.
Le projet APACHE : Athapascan et Inuktitut
1. Athapascan : une interface de programmation pour les applications parallèles
Athapascan-1 propose une
interface de programmation parallèle, indépendante de l'architecture. A partir
d’un fichier source écrit en C++, il est possible de générer un exécutable qui
pourra être lancé aussi bien sur une machine séquentielle standard que sur SMP
(Symetric Multi-Processor) ou sur grappe de PC . L’utilisation d’Athapascan par
le programmeur est simple puisqu’elle repose seulement sur 2 mot clefs :
Fork et Shared.
Le programmeur va déclarer
des procédures appelées tâches. Ces tâches sont appelables à distance à l’aide
du mot clef Fork.
Ces
tâches peuvent accéder à des objets partagés déclarés à l’aide du mot clef shared. Elles doivent cependant
déclarer le type d’accès qu’elles effectueront sur ces objets. Plusieurs types
d’accès sont disponibles :
·
lecture
uniquement (R)
·
écriture
uniquement (W)
·
mise
à jour (R_W)
·
accumulation
(CW) : écriture concurrente, par accumulation à l’aide d’une fonction supposée
associative et commutative par le système.
Le
système est alors capable de détecter automatiquement le parallélisme, et les
synchronisations entre les tâches. Un algorithme d’ordonnancement est ensuite
chargé de placer les tâches sur les processeurs disponibles en tenant compte de
ses contraintes.
Il
n’existe pas d’algorithme d’ordonnancement (ou placement) universel, il est
donc nécessaire d’adapter celui-ci à son problème, mais aussi à l’architecture
sur laquelle le programme sera exécuté.
Athapascan fourni un certain nombre d’algorithmes de placements mais donne aussi la possibilité au programmeur d’intégrer son propre algorithme.
L’implantation d’une telle
bibliothèque, nécessite à la fois l’utilisation de processus légers pour tenir
compte du parallélisme SMP, mais aussi l’utilisation d’une bibliothèque de
communication efficace. Inuktitut a été conçu pour remplir ces fonctionnalités.
2. Inuktitut
2.1 Présentation et Objectifs
Le projet Inuktitut [4] est actuellement développé au sein du laboratoire ID-IMAG. L’objectif de ce projet est de réaliser un intergiciel simulant une machine virtuelle sur une grappe de PC. Plusieurs types de réseau et de protocoles de communication sont utilisés tels que TCP/IP, MPI, CORBA. Les thèmes de recherche abordés au sein du projet sont notamment :
- le déploiement d’applications parallèles et distribuées,
- la réalisation d’une machine virtuelle et
- l’implantation d’une interface de programmation de haut niveau.
Inuktitut se veut indépendant vis-à-vis des architectures cibles, sa conception sous forme de modules permet d’avoir des bibliothèques indépendantes et réutilisables dans d’autres domaines. Les interfaces (Threads, communication, …) sont minimales afin de faciliter le portage et le développement. L’objectif d’Inuktitut est d’obtenir des implantations performantes (1% de dégradation au plus).
Dans un souci d’hétérogénéité, l’application fonctionne sur des architectures de type grappes ayant des nœuds multiprocesseurs et un réseau quelconque. De plus, elle supporte tous les systèmes d’exploitation existant (Linux, Unix, Windows, MacOSX).
2.2 Fonctionnalité
Pour exploiter au mieux les ressources, Inuktitut gère deux niveaux de parallélisme : le parallélisme intra-nœud et le parallélisme inter-nœud. Le parallélisme intra-nœud est réalisé par l’utilisation de processus légers ou threads. Ainsi chaque nœud, constitué d’un multiprocesseurs (SMP), est exploité au maximum de ses capacités. Le parallélisme inter-nœud est exploité grâce à la communication entre les nœuds par échange de message.
Inuktitut propose plusieurs interfaces permettant la manipulation des threads. La première interface, de bas niveau, permet l’utilisation de threads Posix, leur utilisation étant très répandue. Cependant ces threads étant difficiles à utiliser, une deuxième interface propose une abstraction objet des threads, identique à celle fournie dans Java [?].
Les protocoles de communication sont basés sur un principe d’appel de procédure à distance, ils sont détaillés ci-dessous.
2.3 Fonctionnement des appels à distance ou message actif

Le modèle de communication basé sur des appels à distance, aussi appelé message
actif, est très différent d’un modèle basé sur l’envoi et la réception de
message (send/receive). Un appel à distance peut se comparer à un envoi de
message provoquant, sur la machine destinataire, l’exécution d’une fonction de
manière asynchrone.
Le fondement de base des appels distants [8] est que l’arrivée d’un message provoque l’exécution d’une procédure dont le message est le paramètre (cf figure 7). Typiquement un message actif est composé de l'identificateur de l'émetteur, du nom (ou numéro de service) de la fonction traitante du message actif (la procédure à exécuter sur réception du message actif) et par un certain nombre de paramètres pour cette fonction. Malgré la similitude avec l'appel de procédure à distance (RPC : Remote Procedure Call), le message actif a un objectif différent. Son rôle principal est d'extraire les messages de l'interface réseau et de les insérer le plus vite possible dans le calcul. La détection de l'arrivée d'un message actif peut être faite soit par interruption soit par scrutation. Les différences entre ces deux méthodes ainsi que le choix réalisé dans Inuktitut sont expliqués dans le paragraphe décrivant la conception du routeur du chapitre « Architecture d’Inuktitut ».
L’acquisition des messages pose un problème spécifique. En effet, il est nécessaire de localiser l’emplacement mémoire où celui-ci doit être mis. Dans la technologie « classique » des communications (TCP/IP par exemple), le message est acquis dans un tampon intermédiaire du système ou rejeté faute de tampon. L’application vient retirer le message des tampons. Cependant, cette méthode est devenue inacceptable car
- la recopie systématique du message interdit l’exploitation efficace des réseaux haut débit.
- La réactivité obtenue pour une application de calcul ou de mouvement de données distribuées est faible.
C’est pourquoi, différents protocoles de communication sont apparus : les Active Message (AM), les Write and Signal (WS) et les Allocate Write and Signal (AWS). Nous allons brièvement décrire la façon dont un message peut être acquis et les contraintes associées. Généralement, tout message est véhiculé sur un réseau en un ou plusieurs paquets élémentaires dont l’entête formée par le premier paquet contient la description du message. Le premier paquet doit être reçu et décodé. Il doit être possible de déduire le nombre de paquets suivants et la zone de mémoire où les mettre avant leur arrivée.
- si c’est possible, on reçoit les paquets directement dans leur zone de destination finale. On parle de communication zéro-copie (les paquets n’ont pas à être copiés dans un tampon avant d’être mis en mémoire).
- Si c’est impossible, il y aura des copies des premiers paquets dans des tampons. Un mécanisme de contrôle de flux doit alors interdire de se trouver dans le cas où aucun tampon n’est disponible pour y mettre le paquet.
Une méthode simple est de n’émettre que le paquet descripteur. Le reste est émis à la réception d’un acquittement qui n’est envoyé que lorsque la zone de réception est connue. Elle a l’inconvénient de nécessiter plusieurs allers et retours dans le réseau pour l’émission d’un message. C’est sur ce principe que les messages actifs d’Inuktitut limitent le plus possible les copies lors de l’envoi et de la réception des messages. Par exemple, si la capacité du réseau le permet, aucune copie des données n’est réalisée, celles-ci sont extraites directement en zone mémoire. Ainsi Inuktitut propose deux types de transmission de données : les données immédiates et les données différées.
Lors de la réception, les données immédiates sont copiées dans un tampon avant d’être placées en zone mémoire. Ceci permet d’accéder à la donnée dès le début de réception du message. Au contraire, les données différées sont placées directement en zone mémoire sans recopie (méthode zéro-copie). Cependant elles ne sont accessibles que lorsque le message a complètement été reçu. Ce principe de zéro-copie permet donc d’obtenir de meilleures performances lors de la réception d’un message. Pour des données de taille importante, il est donc préférable d’utiliser les données différées. Cependant, certains cas nécessitent l’utilisation de données immédiates. C’est par exemple le cas lorsque l’on veut passer dans un message un tableau dont l’application recevant le message ne connaît pas la taille. Ainsi les données immédiates devront indiquer la taille de ce tableau afin de réserver l’espace mémoire nécessaire au stockage des données différées (contenant les valeurs du tableau), ces données étant stockées directement dans leur emplacement mémoire définitif.
Nous allons maintenant expliquer le fonctionnement, les points communs ainsi que les différences entre les trois différents protocoles d’appel à distance AM, WS et AWS (cf. tableau 1). Chacun des protocoles permet d’appeler des procédures, appelées aussi services, à distance. Ces appels sont asynchrones (pas d’attente de résultat) et les paramètres sont passés dans le message. Les différents services sont identifiés par un numéro et doivent au préalable avoir été enregistrés auprès d’un annuaire appelé serviceManager sur tous les nœuds.
L’envoi d’un message est identique quel que soit le protocole utilisé. Il peut être asynchrone d’où la possibilité d’exécuter une fonction, appelée callback, lorsque l’envoi est achevé. L’envoi est constitué de cinq étapes :
- Description des données à envoyer aussi appelées IOVecteur (cf. figure 8).
- choix du protocole utilisé (AM, WS, AWS),
-
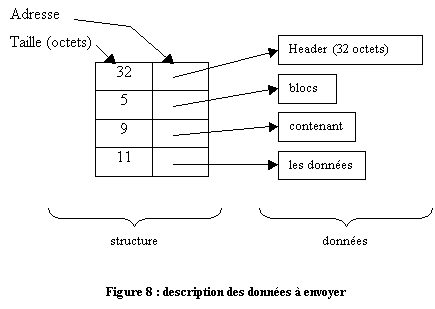
formation de la requête
(construction entête + remplissage du contenu de l’IOVecteur). On a vu
précédemment que deux types de données peuvent être passées dans la
requête : les données immédiates et les données différées. Les données
immédiates sont insérées dans le message grâce à la fonction pack(char* buffer, int taille). Les
données différées sont insérées dans le message grâce à la fonction put(char* buffer, int taille). Le
message est ensuite mémorisé dans un vecteur contenant des éléments de la
forme (taille, adresse):
- envoi du message au nœud distant,
- exécution de la fonction de callback. Cette fonction est appelée une fois l’envoi du message achevé. Elle est passée en paramètre lors de la construction du message.
|
|
Données |
|
Client (coté émission) |
|
Serveur (coté réception) |
||
|
|
|
|
Application |
Réseau |
|
Réseau |
Application |
|
|
|
|
|
|
|
|
|
|
AM |
Immédiates |
|
Alloue/libère |
Réalloue/libère (copie) |
|
Alloue/libère |
Réalloue/libère (copie) |
|
Différées (structure vecteur) |
|
- |
Alloue/libère |
|
Alloue/libère |
- |
|
|
Différées (Contenu vecteur) |
|
Alloue/libère |
- |
|
Alloue/libère |
- |
|
|
|
|
|
|
|
|
|
|
|
WS |
Immédiates |
|
Alloue/libère |
Réalloue/libère (copie) |
|
Alloue/libère |
Réalloue/libère (copie) |
|
Différées (structure vecteur) |
|
- |
Alloue/libère |
|
Alloue/libère |
- |
|
|
Différées (Contenu vecteur) |
|
Alloue/libère |
- |
|
- |
Alloue/libère |
|
|
|
|
|
|
|
|
|
|
|
AWS |
Immédiates |
|
Alloue/libère |
Réalloue/libère (copie) |
|
Alloue/libère |
Réalloue/libère (copie) |
|
Différées (structure vecteur) |
|
- |
Alloue/libère |
|
Alloue/libère |
- |
|
|
Différées (Contenu vecteur) |
|
Alloue/libère |
- |
|
Alloue |
Libère |
|
Tableau 1 : allocation et libération des espaces mémoires en
fonction du protocole de communication utilisé.
Sur réception du message, le serveur décode l’entête, puis s’occupe de la gestion des données. Les données immédiates sont gérées de la même façon quel que soit le protocole utilisé. Ces données sont récupérées par appel à la fonction unpack() (elles sont reçues dans l’ordre dans lequel elles ont été insérées lors de l’appel à la fonction pack()). Cependant, pour des données de taille importante, il est préférable d’utiliser les données différées car ces données ne sont jamais recopiées afin d’améliorer les performances. La gestion des données, lors de la réception du message, est différente en fonction du protocole de communication utilisé (cf tableau 1).
L’espace mémoire contenant la structure du vecteur et celui contenant les données immédiates est toujours alloué/libéré de la même manière. Cependant les données différées sont allouées différemment en fonction du protocole utilisé (cf. tableau 1). Lors de l’utilisation d’un AM, c’est le réseau qui alloue et libère l’espace mémoire contenant la structure ainsi que les données de l’IOVecteur. Si le protocole choisi est WS, l’emplacement des données différées est géré par l’application. Enfin si le message actif est de type AWS, le réseau alloue l’espace mémoire des données immédiates mais c’est à l’application de libérer cet espace.
Les trois protocoles se différencient dans la durée de vie des données reçues. Lors de l’utilisation d’un AM, les données sont accessibles durant l’exécution du service appelé. Si les données ne sont pas recopiées, elle sont perdues à la fin de l’appel du service. Au contraire, les protocoles AWS et WS écrivent directement dans l’espace d’adressage de l’application ainsi, ils permettent l’utilisation des données une fois le service terminé. Pour cela, c’est à l’application de gérer l’espace mémoire des données. Cependant, certains réseaux tels que CORBA réalise déjà l’allocation des données. Ainsi on utilisera le protocole AWS sur un réseau tel que CORBA alors que le protocole WS sera plutôt utilisé sur un autre réseau.
2.4 Architecture d’Inuktitut
Pour des raisons de portabilité et d’extensibilité logicielle, Inuktitut est composé de plusieurs modules. Ces modules permettent de constituer plusieurs bibliothèques. L’utilisation d’une bibliothèque suit toujours le même principe. Premièrement, il est nécessaire de procéder à l’initialisation du module (cf. Annexe I). Après cet appel, le paquetage est utilisable, toutes ses fonctions peuvent être appelées. Pour terminer l’application, le module devra être fermé par l’appel à la fonction terminate().

Voici la structure générale d’Inuktitut :
Nous allons maintenant énumérer chaque module et donner leurs fonctionnalités respectives.
Le noyau générique de communication Network décrit l’interface commune à tous les réseaux, il gère également l’enregistrement des services (fonctions d’appel à distance), ainsi que l’initialisation des réseaux. Cette phase comprend l’initialisation des différents modules d’Inuktitut et pour les modules de communication elle procède à l’interconnexion (création des canaux de communication) des nœuds. Plusieurs modules implantent l’interface réseau de Network : TCP_net, Spread, CORBA.
Lors de l’initialisation, quel que soit le réseau utilisé, les nœuds doivent pouvoir s’échanger des informations. Dans le cas de réseaux TCP, les informations nécessaires sont l’adresse IP et le numéro de port sur lequel le nœud attend la connexion.
On distingue deux types d’initialisation pour les modules réseaux : l’initialisation primaire et l’initialisation secondaire.
Lors d’une initialisation primaire, les informations nécessaires sont échangées grâce à l’utilisation de différentes méthodes telles que NFS (pour TCP_net) ou rsh (pour Spread). Un réseau primaire a l’avantage de pouvoir fonctionner seul.
Au contraire, l’initialisation secondaire nécessite la présence d’un autre réseau, appelé réseau de base, pour fonctionner. En effet, l’échange des informations se réalisera par l’intermédiaire du réseau de base (cf. figure 10). Ce type d’initialisation a pour inconvénient de dépendre d’un autre réseau. Cependant il a l’avantage d’avoir une initialisation plus rapide. Lors de l’initialisation du réseau secondaire, le réseau de base doit avoir achevé sa phase d’initialisation afin de permettre l’échange de messages actifs. C’est pourquoi l’ordre d’initialisation des modules est d’une grande importance. Ces appels sont réalisés dans l’ordre par le module Network.

Le module TCP_net, dont la conception fait partie de notre magistère, établit un réseau de liaisons TCP complètement maillé. L'initialisation de ce réseau est plus coûteuse que celle d'un réseau partiellement maillé. Cependant, le maillage complet permet d’obtenir de meilleures performances lors des communications entre les nœuds.
Dans le cas d’un maillage complet, le routage est inutile puisqu'il existe toujours un chemin direct pour accéder à un noeud donné. Ce réseau possède trois initialisations différentes : une initialisation primaire et deux secondaires.
- L'initialisation primaire de TCP_Net consiste à réaliser toutes les connexions qui sont également appelées channel, en communiquant par fichiers. Chaque noeud lance une écoute sur un port. Puis il écrit ce numéro de port ainsi que son adresse IP dans un fichier dont le nom contient son numéro de noeud. Dans un troisième temps, il lit les fichiers des nœuds avec lesquels il veut se connecter. Connaissant le numéro de port d'écoute et l'adresse du noeud distant, il peut alors réaliser la connexion. Cette méthode est possible car les fichiers sont accessibles par tous les nœuds grâce au système de partage de fichiers NFS. Cependant, ce système est lourd et coûteux (cf. paragraphe dynamicité du chapitre Evaluation de performance).
- Les deux autres initialisations sont des initialisations secondaires. Cela signifie qu'elles ont besoin d'un autre réseau (appelé réseau de base) afin que les nœuds puissent se découvrir et communiquer entre eux. Le principe est identique à l'initialisation primaire (Chaque noeud lance un port sur lequel il attend les demandes de connexion). Seul le moyen de communication est modifié. En effet, les communications ne se font plus par fichiers partagés mais par échange de messages actifs circulant sur le réseau de base (cf figure 2). Le nœud 5 à l'initiative de l'ouverture de la connexion envoie au noeud distant un message actif (d) dans lequel il écrit son adresse IP et son numéro de port. Sur réception de ce message (f), le noeud distant réalise la connexion (g). Parmi les initialisations secondaires, l'une réalise une initialisation statique, l'autre une initialisation dynamique. La première (statique) ouvre toutes les connexions (réseau complètement maillé) lors de l'initialisation du réseau tandis que l'autre (dynamique) n'ouvrira une connexion que lorsqu’il devra parler au nœud distant. La partie dynamicité de TCP_net sera détaillée plus tard.
Les deux modules Spread et
TCP_net (cf. Annexe I) implantent également une barrière, nécessaire à la
synchronisation des nœuds. Ainsi l'appel à la fonction barrier() bloquera le programme sur cette fonction jusqu'à ce que
tous les nœuds soient bloqués. Son principe de fonctionnement est simple (cf.
figure 11). Il est basé sur la communication par messages actifs. Il utilise
deux services (types de messages). Lorsqu'un noeud arrive sur l'instruction barrier(), il envoie un message au nœud
0, puis se bloque en attendant la réception d'un acquittement. Le noeud 0
attend les acquittements de chaque nœud. Enfin, il diffuse un 
message afin que les nœuds se débloquent et passent la barrière.
De même les modules Spread et TCP_net implantent un module appelé routeur. Ce module gère le routage des messages dans Spread. Il construit une table de routage lui indiquant le lien sur lequel envoyer le message en fonction du nœud destinataire. Le module routeur gère également la réception des messages. Sur réception d’un message, il regarde si celui-ci lui est destiné. Si c’est le cas, le routeur appelle le service correspondant au message actif reçu. Sinon, il consulte sa table de routage et propage le message sur le lien permettant d’atteindre le nœud voulu. La réception de message peut être implanté de deux façons. La première est basée sur le traitement par interruption (lors de l'arrivée d'un message, une interruption est générée et le message est traité). La deuxième méthode utilise une fonction système appelée select(). Cette fonction prend en paramètre une liste de descripteurs de fichiers, puis elle endort le thread jusqu’à ce qu’elle détecte un changement d’état sur un des descripteurs. Des études ont montré que le traitement par interruption est moins efficace que l’utilisation de la fonction système select(). C'est pourquoi nous avons choisi cette méthode pour détecter l’arrivée des messages. Le thread est bloqué sur la fonction select() en attente de message. Lors d’un changement d’état des descripteurs, le thread est réveillé puis, il déchiffre l'entête et appelle la fonction correspondante au service indiqué dans l’entête.
Les deux modules Spread et TCP_net seront plus détaillés dans le chapitre « Passage à l’échelle et dynamicité ».
Un module nommé Psocket, que nous avons également réalisé au cours de notre stage, forme une couche de portabilité pour l’utilisation des « sockets ». Cette bibliothèque indépendante est portable sur les API bas niveau de différents systèmes cibles (les sockets Posix et les sockets WIN32).
Deux autres modules intitulés Pthread et Jthread s’occupent de la gestion des threads. Ils gèrent les threads Posix ainsi que les primitives de synchronisation.
Enfin, un autre module, nommé Tracer, sert à faire de l’évaluation de performance ainsi qu’à des fins de débogage. Lors de l’exécution d’un programme Inuktitut, ce module crée des fichiers dans lesquels il écrit les états des différents threads, les moments d’activité… Les enregistrements réalisés par le tracer sont optimisés de façon à ne pas perturber le programme. De plus, pour inhiber totalement l’influence sur les performances, les traces peuvent être désactivées.
2.5 Exemple de programme Inuktitut :
Pour mieux comprendre l’utilisation d’Inuktitut, voici un algorithme effectuant l’initialisation d’un réseau TCP_net. Ensuite, le nœud numéro 1 envoie un message actif au nœud de numéro 0 qui affiche ensuite à l’écran les données immédiates puis les données différées.
//Il est nécessaire d’importer les
fichiers de déclaration Inuktitut
//Classe décrivant un service, elle implante
une fonction virtuelle qui sera exécutée lors de
//la réception d’un message actif
correspondant à ce service.
Code du Service
void call (
Header* h, //Pointeur sur l’entête du message
IOVectEntry*
iov, //Pointeur sur un vecteur contenant les
données
//
différées
IOVectSize iov_sz //Taille du vecteur
)
{
//On
alloue un tampon de réception pour les
données immédiates
allocation(buf) ;
//Récupération de la donnée immédiate dans
le tampon et affichage de celle-ci
unpack(buf);
affiche(buf) ;
//Récupération de la donnée différée
affiche(iov[0].data)
//On indique au programme principal que le message est reçu et que le
//programme peut se terminer
isterm <- true;
}
Code du programme
principal
//Déclaration d’un objet service
ObjetService Oservice;
//Déclaration du réseau de communication
TCP_net reseau;
//Initialisation du réseau
//(La fonction prend en paramètre le numéro du nœud ainsi que le nombre de nœuds
//du réseau)
reseau.initialize( &argc,&argv );
//Enregistrement du service auprès de serviceManager, service recensant tous les
//services pouvant être utilisés avec les messages actifs.
//Cet enregistrement doit être réalisé avant la fin d’initialisation du réseau sur tous les
//nœuds
ServiceManager.bind (&Oservice);
//Fin de la phase d’initialisation du réseau TCP_net
//Le réseau peut maintenant être utilisé
//Si on est le nœud 1, on envoie le message actif
si (mon numéro de noeud = 1) alors
{
//Déclaration d’un message actif associé au service Oservice
ActiveMessage am (reseau, Oservice);
//Insertion des données immédiates dans le message
//Ces données sont passées par copie
am->pack(Données immédiates);
//Insertion des données différées dans le message
//Ces données sont passées par référence
am->put(Données différées) ;
// Récupération du channel sur lequel écrire pour atteindre le nœud 0
//sur le réseau net
Channel = reseau.get_default_route(0);
//Envoi du message sur le channel récupéré
post(am);
} //Fin du code exécuté par le nœud 1
//Le nœud 0 ne doit pas terminer avant de
recevoir son message (sinon il appellerait
//la fonction terminate() et fermerait ses connexions. Donc il exécute une boucle //d’attente active.
si (mon numéro de nœud = 0) alors
{
tant que (!isterm)
{
//le thread s’endort un certain temps
}
}
//Fermeture des connexions …
reseau.terminate();
}
Passage à l’échelle et dynamicité
1. Lancement
La problématique du lancement d’applications distantes est la rapidité du lancement de cette application sur l’ensemble de la grappe (ou grille de grappes) . La plupart des outils existants utilisent des protocoles d’exécution distantes dédiés. Cette solution, bien que performante, impose aux différentes grappes de la grille de posséder une politique de sécurité commune. C’est pourquoi il est intéressant de remplacer ces protocoles dédiés par des protocoles d’exécutions distante standards.
|
|
Passage
à l’échelle |
Protocole
d’exécution distante |
Mode |
|
C3 |
Limité au nombre de processus tolérés par le système |
Standard (ssh et rsh) déconnecté |
Déconnecté |
|
Rexec |
Limité au nombre de connexions ouvertes, tolérées par le système |
Dédié |
Déconnecté + service d’annuaire |
|
Yod |
Validé sur Asci-red avec 1010 nœuds |
Dédié |
Connecté |
|
SCUPP |
Tests jusqu’à 256 nœuds |
Dédié |
Pré-connecté |
|
Globus |
Validé sur 2000 nœuds |
Dédié |
Déconnecté + service d’annuaire |
Tableau 2 Caractéristiques des principaux lanceurs d’applications
existants pour grappes ou grilles de grappes. [10]
Le lanceur C3 est le seul à
utiliser des protocoles standards. Le problème rencontré par C3 est que pour
chaque demande d’exécution distante un processus est lancé. Cette méthode
charge énormément la machine effectuant ces requêtes, et est limitée par le
nombre de processus maximum autorisés pour un utilisateur par le système. Donc
le lanceur C3 ne passe pas à l’échelle d’une grille.
Les autres solutions utilisent un protocole d’exécution distante dédié. Rexec, GlobusRun et Yod proposent un ensemble de démons gérés par un système d’annuaire. L’interconnexion de ces démons a lieu à chaque demande d’exécution. Une grappe voulant participer à une grille fonctionnant avec cette méthode doit donc modifier sa configuration pour en faire partie. De plus, l’utilitaire Rexec effectue toutes les requêtes d’exécutions à distance à partir du nœud initial. Le nombre de nœuds total se retrouve donc borné par le nombre de connexions réseaux maximum tolérés par le système.
Le module Spread d’Inuktitut utilise un lanceur optimisé basé sur les
protocoles d’exécution distante standards rsh/rshd, ssh/sshd, ou autres. Un des
avantages de cette solution est que les problèmes de sécurités sont
reportés sur ces protocoles.
Lors d’un appel d’exécution distante, la partie la plus coûteuse est l’authentification de l’utilisateur. Il est donc nécessaire de paralléliser cette authentification. Cette parallélisation peut se faire à deux niveaux : paralléliser la séquence d’appel et exploiter le nombre de machines en distribuant ces appels sur les autres nœuds.
a) Parallélisation
locale de la séquence d’appel

Figure 12 :
parallélisation des appels en local
Pendant le temps
d’attente de l’acquittement de l’authentification, au lieu d’être bloqué le
lanceur envoit d’autres appels d’authentification vers d’autres nœuds. Les
appels sont donc pipelinés ce qui permet d’en lancer plus en moins de temps.
b) Distribution des
appels sur les nœuds
Au lieu qu’une seule machine lance les appels sur
tous les nœuds, les appels vont être fait de manière récursive. Le premier nœud
fait n appels distants, les n nœuds touchés par cet appel vont a leur tour
lancer n nœuds et ainsi de suite. Une topologie en arbre binaire comme en arbre
binomial peut être utilisée. L’arbre binomial est plus intéressant au niveau du
coût, il est de l’ordre de log2(N). Voyons donc les étapes du
lancement avec un arbre binomial :

Etape 1

Etape 2
Il y a maintenant 4 nœuds capables d’effectuer un
lancement distant …
Etape 3
Figure 13 : Décomposition du
lancement avec un arbre binomial
Ces deux méthodes d’optimisation répondent à des
problèmes différents. La parallélisation des appels permet d’être plus
performant, mais consomme beaucoup de ressources (CPU et connexions réseaux).
Tandis que la méthode arborescente est moins performante, mais consomme très
peu de ressources. De ce fait, il est possible de mixer ces deux approches afin
de trouver un compromis adapté à l’architecture des grappes ou grilles de
grappes cibles.
2. Interconnexion
Créer un réseau de
communication complètement maillé dès le lancement d’une application est très
coûteux. En utilisant un réseau primaire, comme celui initialisé par le module
Spread, on peut dynamiquement créer les connexions nécessaires. Pour limiter la
consommation des ressources réseaux il faut s’adapter à l’application lancée,
mais aussi à l’architecture du réseau physique ainsi qu’aux capacités des
machines.
Le premier intérêt
avec l’utilisation de connexions dynamiques est de pouvoir adapter les liaisons
à l’application lancée sur la grappe. En effet, selon les applications on peut
avoir des besoins très différents aux niveaux du nombre ou de la durée de vie des
connexions. Alors que certaines applications nécessitent une communication
entre tous les nœuds en permanence, d’autres sont orientées autour d’un nœud
maître, c’est-à-dire que toutes les communications se font seulement entre un
nœud et tous les autres. Certaines applications sont récursives et nécessitent
un réseau de communication sous forme d’arbre, d’autres demandent par
intermittence des connexions pour très peu de temps ou nécessitent une
topologie des connexions qui évolue selon l’avancement dans le temps.
Un autre avantage dans
l’utilisation de connexions dynamiques, est de pouvoir adapter le réseau
virtuel à la topologie du réseau physique. Par exemple, pour une application
fonctionnant sur une grille comprenant deux grappes, il peut être intéressant
de coller les connexions au réseau physique en ne réalisant qu’une seule
liaison permettant la communication entre les deux grappes. Il est ensuite
nécessaire de procéder au routage des messages afin que chaque nœud puissent
communiquer avec tous les autres.
De plus, l’utilisation de connexions dynamiques permet de limiter le nombre de connexions ouvertes et ainsi s’adapter aux contraintes des systèmes. En effet le nombre de ports d'une machine est limité en fonction du système d’exploitation utilisé. Par exemple, Linux limite à 1024 le nombre de ports ouverts ainsi, une grappe de plus de 1024 nœuds ne peut pas supporter un maillage complet. De plus, un nombre de sockets important entraîne une perte de réactivité du réseau (le réseau réagit moins rapidement car il doit écouter sur plus de sockets d'où une baisse de performances).
C'est pour des raisons qu’une gestion dynamique des liaisons a été ajoutée dans TCP_net. Cette gestion commence par une initialisation dynamique du réseau. Celle-ci n'ouvre aucune connexion lors de l'initialisation. Les connexions ne seront réalisées que lorsque cela sera nécessaire, c'est-à-dire lorsqu'une communication aura lieu entre les deux nœuds.

Toutefois, les ouvertures dynamiques de connexions conduiront à un maillage
complet du réseau, ce qui ne résout donc pas les problèmes. Dans un premier
temps, TCP_net ne ferme pas les connexions ouvertes avant la terminaison du
programme. Dans un deuxième temps, il sera nécessaire de limiter le nombre de
connexions ouvertes simultanément. Une fois cette limite atteinte, il est
nécessaire de procéder à la fermeture de l’une des connexions ouvertes. Ceci
implique le problème du choix de la connexion à fermer. Plusieurs politiques
peuvent être à priori adoptées : la politique FIFO (la première connexion
ouverte sera la première fermée), la politique LRU (Least Recently Used :
la connexion ayant été utilisée le moins récemment sera fermée), ou encore la
fermeture de la connexion sur laquelle le moins de message ont transité. La
politique efficace dépend du comportement de l'application. La politique LRU
semble être la plus générale. C'est donc en suivant cette politique que TCP_net
gèrera les connexions dynamiques.
Une fois la connexion choisie, il faut trouver comment procéder proprement à sa
fermeture. Les liaisons étant de type TCP bidirectionnelles, les nœuds de
chaque côté de la liaison doivent demander explicitement la fermeture de la
connexion. Pour cela nous avons établi un protocole de fermeture de liaison
(cf. figure 14 et 15). Le nœud 1 à l’initiative de la fermeture de connexion
envoie au nœud 2 un message actif de type Close puis s’interdit l’utilisation
de cette connexion. Sur réception du message, le nœud 2 envoie un acquittement
au nœud 1 puis ferme la liaison. A la réception de l’acquittement, le nœud 1
procède à son tour à la fermeture de la liaison. Avec ce protocole, un seul
problème peut survenir : les deux nœuds demandent la fermeture
simultanément et les paquets Close se croisent sur le réseau (cf. figure 15).
Pour remédier à cela, le protocole considère que si un nœud a déjà envoyé sa
demande de fermeture et qu’il reçoit un message de type Close, ce message est
interprété comme un acquittement et le nœud ferme la liaison.
La dynamicité des connexions est indispensable à la gestion dynamique des nœuds (ajout et suppression de nœuds) ainsi qu’à la fusion/séparation de plusieurs machines virtuelles en une seule. Ces types de dynamicité, prévus dans les objectifs d’Inuktitut, sont d'autant plus performant que de nombreuses applications n’utilisent que quelques connexions entre certains nœuds [?].
Evaluation de performances
Les tests ont été réalisés sur la grappe icluster du laboratoire ID-IMAG (cf. Annexe II). Chaque nœud de la grappe est composé d’un ordinateur muni d’un processeur Pentium III d’une puissance de 733Mhz. Les nœuds sont interconnectés par un réseau Ethernet 100Mhz commuté.
1. Passage à l’échelle
cf partie
de Marie laure
2. Dynamicité
2.1. Evaluation du coût en fonction du nombre de liaisons utilisées
Ce test permet de comparer le temps réalisé sur différents réseaux en fonction du nombre de communication demandées par l'application. Il a été testé sur des réseaux TCP_net secondaire initialisés par un réseau de base de type spread.
Mesures réalisées
Le temps mesuré comprend l'initialisation du réseau spread, l'initialisation du réseau secondaire TCP_net, une phase de communication entre les nœuds et la terminaison des deux réseaux. La phase de communication entre les nœuds réalise l'envoi d'un nombre variable de message. Chaque message envoyé circule sur une liaison différente. Ainsi, l'utilisation du réseau dynamique implique l'ouverture d'une liaison à chaque envoi de message. Alors que le réseau statique créer toutes les connexions dans sa phase d'initialisation.
Résultats et interprétation
Le test a été lancé sur 91 nœuds. Chaque point de la courbe a été obtenu en effectuant une moyenne sur 10 mesures. Le nombre de message envoyé varie entre 0 et le nombre maximum de connexions que l'on peut créer sur un réseau de 91 nœuds. C'est-à-dire que l'on a envoyé au maximum 4095 (= N*(N-1)/2 pour N nœuds) messages. Le coût de transit des messages et faible par rapport au coût d'établissement des liaisons (l'établissement d'une liaison dure environ 0.033 secondes), c'est pourquoi le réseau TCP_net statique obtient des résultats à peu près constant. En effet quelque soit le nombre de messages envoyés, les 4095 liaisons sont réalisées lors de l'initialisation du réseau statique. Le réseau TCP_net dynamique est plus performant car il ne créer que les connexions nécessaire. Ainsi pour M messages envoyés, le réseau dynamique ne crée que M liaisons alors que le réseau statique a créé les 4095 canaux nécessaire au maillage complet du réseau.
.

On
peut remarquer que le coût du réseau dynamique est proportionnel au nombre de
canaux utilisés, qui correspond dans notre test au nombre de messages envoyés.
2.2. Multidiffusion sur les différents réseaux
Ce test permet de comparer les trois différents types de réseaux sur lesquels nous avons travaillés : le réseau TCP_Net avec une initialisation secondaire statique, le réseau TCP_net avec une initialisation secondaire dynamique et le réseau spread. Les initialisations secondaires sont réalisées à partir d’un réseau virtuel primaire de type spread. Le programme test effectue un All to All sur l’ensemble des nœuds. C’est-à-dire que chaque nœud va envoyer à chaque autre nœuds un message actif ne contenant aucune donnée.
Mesures réalisées
Les temps réalisés sont mesurés sur le nœud de numéro 0. Une barrière permet au nœud 0 d’attendre que tous les nœuds aient bien reçus l’ensemble des messages envoyés.
Les valeurs obtenues mesurent le temps total de l’application. Ce temps comprend la phase d’initialisation, l’échange des messages et la phase de fermeture du réseau. Lors de l’utilisation d’un réseau secondaire (réseau TCP_net statique et dynamique), la mesure inclut également le temps mis pour initialiser le réseau primaire.
Ce test permet de comparer l'efficacité des réseaux TCP_net statique et dynamique dans des conditions stressantes. En effet, de nombreux messages vont transiter sur le réseau (22350 messages sur 150 nœuds).
Résultats et interprétation
Le test a été lancé en faisant varier le nombre de nœuds de 1 à 150. Chaque point de la courbe a été obtenu en effectuant une moyenne sur 20 mesures.


On peut tout d’abord remarquer que les
temps réalisés par le réseau spread sont les meilleurs. Ceci est dû au fait que
spread est un réseau arborescent et donc il n’est pas complètement maillé.
Ainsi il a beaucoup moins de liaisons à ouvrir que les réseaux TCP_net statique
et dynamique et l’initialisation du réseau est plus rapide (le coût d'ouverture
d'un liaison est d'environ 0.033 secondes). En effet alors qu’un réseau
complètement maillé doit ouvrir 11175 liaisons pour 150 nœuds (= N*(N-1)/2 pour
N nœuds), le réseau spread n’ouvre que 149 liaisons (= N-1 pour N nœuds) en
construisant un arbre à plat couvrant. Cependant les communications de spread
nécessitant un routage, elles sont donc plus coûteuses que des communications
réalisées sur un réseau complètement maillé, ce qui sera pénalisant pour une
application réalisant de nombreuses communications.
On peut ensuite voir que contrairement au premier test, le réseau statique est plus efficace que le réseau dynamique. La meilleure hypothèse expliquant cette différence est que, lors de l’utilisation d’un réseau dynamique, certaines connexions sont ouvertes en doubles. En effet, si deux nœuds veulent simultanément ouvrir leur liaison commune. Chacun des nœuds va envoyer sur le réseau un message de demande d’ouverture de liaison. Les messages se croisant sur le réseau, à la réception des messages, aucun des nœuds ne remarquera qu’une autre liaison est déjà en court d’ouverture (cf. figure 16). Et les deux ouvertures aboutiront.
Puisque certaines connexions sont ouvertes en double, et vu les performances du réseau dynamique lors du premier test, on peut penser qu'une fois ce problème résolu, le réseau dynamique sera aussi efficace que le réseau statique.
2.3. Améliorations et perspectives
Suite à ces tests, on a remarqué que plusieurs améliorations étaient à prévoir sur différents réseaux.

La première consiste à éliminer les
doubles liaisons lors de l’utilisation du réseau dynamique. On a vu
précédemment que dans certains cas, deux nœuds pouvaient réaliser simultanément
une demande de connexion. Un protocole simple peut permettre de résoudre ce
problème. Sur réception d’une demande de connexion, il suffit de vérifier
qu’aucune ouverture de connexion vers ce nœud n’est en cours. Dans le cas où
une ouverture est en cours, il faut procéder à une élection afin de choisir
quelle demande de connexion doit être ignorée. Par exemple, on peut décider que
la demande réalisée par le nœud de plus petit numéro est prioritaire (cf.
Figure 17). En procédant ainsi, seule une liaison est réalisée entre les deux
nœuds.
Une autre amélioration concerne l’ouverture des connexions.
En effet, lors de l’utilisation d’un réseau statique, les connexions sont
réalisées séquentiellement. C’est-à-dire qu’après chaque envoi du message de
demande de connexion, le nœud se bloque en attendant la connexion. Une
parallélisation est possible en envoyant tous les messages de demande de
connexion avant d’attendre que les nœuds distants réalisent la connexion.
TCP_net a également de nouvelles perspectives. Parmi
celles-ci se trouve la création d’un cache de connexion efficace. Pour cela,
une politique LRU doit être implantée afin de gérer correctement les fermetures
de connexions.
Une autre perspective concerne l’ouverture dynamique des
liaisons. On a remarqué qu’avec le réseau dynamique, le premier envoi d’un
message sur une liaison est coûteux car il nécessite la création de cette
liaison. L’objectif serait d’envoyer le message actif par un autre moyen
parallèlement à la réalisation de la connexion pour l’envoi direct de messages
futurs. Deux moyens sont possibles pour procéder à l’envoi du message pendant
la création de la liaison. Le premier consiste à envoyer le message via le
réseau primaire. L’envoi du message sur le réseau secondaire à l’aide de
routage est la seconde méthode. Cependant cette deuxième méthode nécessite que
le graphe couvrant le réseau secondaire soit connexe, ce qui n’est pas le cas
lorsque aucune connexion n’est réalisée. Ainsi la deuxième méthode nécessite
l’utilisation de la première (envoi du message via le réseau primaire) lorsque
le réseau n’est pas connexe.
Conclusions et perspectives
Une version d’Inuktitut est déjà exploitée par la couche supérieure Athapascan. Cependant, une prochaine version devrait gérer un lancement multi-réseaux (un même réseau virtuel utilisant différents types de réseaux physiques). De plus cette nouvelle version devrait supporter l’ajout ainsi que la suppression dynamique des machines. Cette gestion dynamique des nœuds pose le problème du nommage des machines. En effet, comment nommer une nouveau nœud sachant que plusieurs nœuds peuvent arriver simultanément à plusieurs endroit du réseau. Un autre objectif d'Inuktitut vise à permettre, comme Harness, la fusion de deux machines virtuelles ainsi que la séparation d'une machine virtuelle en deux. Ce sont toutes ces perspectives que le projet Inuktitut souhaite atteindre.
Annexes :
Annexe I : Interface du réseau TCP_net (Inuktitut) :
Voici les signatures des principales fonctions présentes dans l’interface de TCP_net :
int
initialize( int* argc, char** argv[]
)
Cette fonction réalise l’initialisation primaire du réseau. Les nœuds communiquent par fichiers accessibles grâce au système NFS. L’initialisation permet d’obtenir un réseau TCP complètement maillé. Cette fonction prend en paramètre son numéro de nœud ainsi que le nombre de nœuds présents dans ce réseau.
int initialize( int* argc, char** argv[], Network* netInit )
Cette fonction réalise l’initialisation secondaire du réseau. Pour créer les connexions, les nœuds communiquent par messages actifs envoyés sur le réseau primaire « netInit ». L’initialisation permet d’obtenir un réseau TCP complètement maillé.
int initializeDynamic(int* argc, char** argv[], Network* netInit)
Cette fonction réalise l’initialisation secondaire dynamique du réseau. Pour créer les connexions, les nœuds communiquent par messages actifs envoyés sur le réseau primaire « netInit ». A la fin de l’initialisation, aucune connexion n’est réalisée. Les connexions seront ouvertes au fur et à mesure en fonction des besoins de l’application.
int
commit ()
Cette fonction doit être appelée pour terminer l’initialisation. Dans le cas de l’initialisation secondaire statique, c’est ici que seront créées les connexions (contrairement à l’initialisation primaire qui les crée dans la fonction initialize()). Ceci est dû au fait que le réseau primaire est utilisé pour initier les connexions. Il doit donc avoir validé son initialisation (réalisée par l’appel à la fonction commit() du réseau primaire), ce qui n’est pas le cas dans la fonction initialize().
int terminate ()throw (NetworkError)
Cette fonction ferme toutes les connexions du réseau. Après l’appel de cette fonction, plus aucune communication n’est possible.
Les quatre fonctions suivantes permettent la gestion de la mémoire :
Request* allocate_request () throw
(BadAlloc)
Void deallocate_request(Request* rq)throw (InvalidArgument)
void* allocate_data( size_t sz )
void deallocate_data( void* data
)
La première alloue l’espace mémoire nécessaire à la requête (allocation de l’IOVecteur ainsi que de la taille de l’entête (32 octets)) (cf. figure 8). La deuxième fonction libère cet espace mémoire. La troisième alloue l’espace mémoire nécessaire au stockage des données. Et la quatrième fonction libère cet espace mémoire.
OutChannel* get_default_route( LocalNodeNo peer
)
Cette fonction retourne le canal permettant d’atteindre le nœud de numéro « peer ». Dans le cas d’une initialisation dynamique, elle regarde si une connexion existe avec ce nœud et dans le cas contraire fait appel à la fonction open_channel(). Avec un réseau qui n’est pas totalement maillé (ex : Spread), cette fonction permet le routage des messages.
OutChannel* open_channel( LocalNodeNo peer )
Si aucune liaison n’est déjà ouverte vers le nœud de numéro « peer », cette fonction ouvre un canal de communication en direction de ce nœud. Sinon, elle retourne le canal existant.
void close_channel( OutChannel* ch )
Cette fonction permet de fermer un canal de communication. Elle peut être appelée en interne (gestion de la dynamicité) ou explicitement par l’application.
void broadcast( Network::Request* req, OutChannel* ch)
Cette fonction envoie le message « req » vers tous les nœuds du réseau.
void post(
Network::Request* req ,OutChannel* ch)
Cette fonction envoie le message « req » sur le canal « ch ».
void
barrier()
Cette fonction permet de réaliser une synchronisation entre tous les nœuds du réseau. Elle est notamment utilisée lors de la phase de terminaison pour synchroniser tous les nœuds.
Annexe II : La grappe du laboratoire ID-IMAG
La grappe du laboratoire ID-IMAG est composée de 225 ordinateurs Pentium III
733 MHZ. Elle est formée d’une artère principale constituée d’un réseau haut
débit sur lequel sont connectés 5 commutateurs. Chaque commutateur relie 45 PCs
sur un réseau Ethernet 100. Les nœuds peuvent communiquer par messages. Ce plus
un système de fichiers répartis est présent sur la grappe. Les applications
sont lancées à distance en utilisant le protocole ssh [?]. L’utilisation de la
grappe est gérée par un système de
réservation des nœuds appelé PBS. Ce système gère des files d’attentes
d’utilisateurs en fonction du nombre de nœuds demandés.
Glossaire :
API (Application Program Interface) : c’est une interface
standard utilisée pour appeler un ensemble de fonctionnalités. Ces interfaces
standards sont notamment utiles pour obtenir une généralisation des
applications. L’API permet de spécifier les interactions avec l’application ou
le code proposant ces interfaces.
DMA (Direct Memory Acces) : L’accès direct à la mémoire est une technique de transfert de données pour laquelle le processeur (CPU) n’a généralement qu’à donner une description du transfert : adresse et taille des données. Il n’a pas besoin d’exécuter d’autres instructions pour déplacer les données. Par exemple, si l’on veut déplacer des données reçues sur la carte réseau afin de les copier sur le disque, on peut utiliser le mode DMA qui attendra que le processeur libère le bus puis utilisera ce bus afin de déplacer les données. Pendant ce temps, le processeur continue à exécuter des instructions.
FDDI : c’est un réseau haut débit câblé en fibre otique. FDDI protocole de communication de type anneau à jeton.
IOVecteur : c’est une structure définie dans Inuktitut qui permet le stockage des messages actifs (cf figure 8). Elle est représentée comme un vecteur contenant des éléments de la forme (taille, pointeur). Le pointeur adresse une case mémoire contenant les données, et le premier paramètre indique la taille de ces données.
Message actif : c’est une architecture de communication
utilisée en programmation parallèle. (cf. chapitre Fonctionnement des appels à
distance ou message actif & Annexe II). Ce type de communication est de
type appel de procédure à distance.
Myrinet : Un réseau Myrinet dispose des technologies suivantes :
commutation de paquets
carte réseau munie d’un processeur RISC pilotant plusieurs contrôleurs DMA
passage de
messages
Posix : acronyme de Portable Operating System Interface for computer environments Posix est un standard sur les interfaces systèmes tels que les threads et les sockets.
Rsh : (remote shell) permet l’appel d’une commande ou d’un programme sur une machine distante.
SCI : les réseaux SCI sont des réseaux à capacité d’adressage caractérisés par les point suivants :
Adressage des mémoires distantes.
Lecture/Ecriture distante sans interrompre le processeur distant.
Plus de nécessité de programmation par échanges de messages
Topologie en grille possible
SMP : c’est l’acronyme de Symétrique MultiProcesseur. Les
processeurs sont utilisés par un même système et peuvent communiquer entre eux
à l’aide de mémoire partagée.
Socket : une socket représente une extrémité d’un lien de communication bidirectionnelle entre deux programmes fonctionnant au-dessus d’un réseau. Une socket est liée à un numéro de port ainsi la couche TCP peut identifier l’application destinataire des données reçues sur le port. C’est une interface générique de communication.
Thread : appelé aussi processus léger, un thread est un programme en cours d’exécution. Un processus peut contenir plusieurs threads. Ils se partagent alors l’environnement d’exécution et peuvent donc communiquer grâce à l’espace d’adressage qu’ils ont en commun. L’utilisation de threads permet de profiter du parallélisme intra-nœud. En effet, lorsqu’un thread est en attente (par exemple attente de libération d’une ressource partagée) les autres threads peuvent continuer leurs calculs. Ceci n’est pas possible sans l’utilisation des threads.
Bibliographie :
[1] A. CARISSIMI : ATHAPASCAN-0 : Exploitation de la multiprogrammation légère sur grappes de multiprocesseurs. Novembre 1999
[2] M. BECK, J.J. DONGARRA, G.E.
FAGG , G.A. GEIST, P. GRAY, J. KOHL, M. MIGLIARDI, K.MOORE, T.MOORE, P.
PAPADOPOULOS, S.L. SCOTT and V. SUNDERAM : HARNESS : A Next
Generation Distributed Virtual Machine. Juin 1998
[3] G.A. GEIST, J.A.KOHL, P.M.PAPADOPOULOS and
S.L.SCOTT : Beyond PVM3.4 : What we’ve learned, what’s next, and why.
[4] J. BRIAT, T. GAUTIER : Inuktitut Présentation. Novembre 2001
[5] R. Namyst : Contribution à la conception de supports exécutifs performants. Décembre 2001.
[6] VIA ? ? ? ? ? ?
[7] SCI ? ? ? ? ? ?
[8] T.von EICKEN, D.E. CULLER, S.C. GOLDSTEIN,
and K.E. SCHAUSER : Active Messages : A mechanism for integrated
communication and computation. Mai 1992
[9] Ian Foster, Carl Kesselman, Steven
Tuecke : The anatomy of the grid.
[10] Cyrille Martin, Wilfrid Billot : Lancement d’applications sur des grappes de grandes taille.
Etudiant : MENETRIEUX
Marie-Laure 2éme
année
MARESCHAL Arnaud 2éme
année
Entreprise : Laboratoire ID-IMAG (Informatique et Distribution)
Adresse : ENSIMAG
– Antenne de Montbonnot
ZIRST 51 av. Jean Kuntzmann
38330 Montbonnot
Téléphone (standard) : Télécopie
:
Responsable
administratif : Olivier RICHARD
Téléphone : Télécopie
E-Mail
:
olivier.richard@imag.fr
Maître de
stage (nom et fonction) :
Téléphone : Télécopie
E-Mail :
Tuteur
enseignant (nom et fonction) :
Téléphone : Télécopie
:
E-Mail :
Titre :
Extension
de l'intergiciel pour le calcul parallèle haute performance : Inuktitut
Résumé :
De nos jours, la complexité des applications informatiques augmente sans cesse. Pour obtenir une puissance informatique suffisante, il devient nécessaire d'assembler plusieurs multiprocesseurs à l'aide de réseaux haut débit. Ces assemblages de multiprocesseurs sont appelés grappes ou grilles de grappes. Chaque multiprocesseur de la grille est appelé nœud. Le laboratoire ID-IMAG s'intéressent à l'exploitation efficace des grappes et grilles de grappes à travers deux projets. Le premier s'intitule Athapascan et a pour objectif de fournir une interface permettant l'utilisation efficace de grilles de grappes. Le deuxième projet, appelé Inuktitut, constitue le noyau de communication et d'exécution d'Athapascan. Il permet également la portabilité de l'intergiciel Athapascan sur la plupart des plate-formes existantes.
Notre stage a pour objectif la réalisation de deux modules constituant Inuktitut. Le premier module s'appelle Psocket et fourni une couche de portabilité au-dessus des sockets Posix. Le deuxième module réalisé s'intitule TCP_net. Il fourni un réseau virtuel complètement maillé de liaisons bidirectionnelles TCP. Le particularité de ce réseau virtuel est de proposer à l'utilisateur une option permettant l'ouverture dynamique des liaisons. Ainsi seuls les canaux utilisés par l'application seront ouverts.
Cette dynamicité des liaisons doit servir de base à l'ajout et au retrait dynamique de nœuds. Elle doit également être utilisée pour permettre la fusion de deux machines virtuelles ainsi que la séparation d'une machine virtuelle en deux.